In diesem Blogeintrag zeigen wir anhand eines minimalen Beispiels, wie man eine Zeitreihenanalyse im SAP Business Application Studio durchführt. Dabei verwenden wir die Bibliothek „hana_ml“. Diese liefert Algorithmen für maschinelles Lernen, welche auf dem Script-Server der SAP HANA ausgeführt werden.
Damit werden wir ein Zeitreihenmodell mit Hilfe einer Tabelle aus der SAP HANA Cloud trainieren und dieses anschließend auf Daten anwenden, um Vorhersagen zu erstellen. Die Vorhersagen schreiben wir dann zurück in die Tabelle auf der SAP HANA Cloud.
Außerdem erstellen wir einen Plot zur Veranschaulichung der Vorhersage. Unser Ziel ist es, einen Einstieg in die Entwicklung mit dem BAS und „hana_ml“ zu liefern.
Datengrundlage
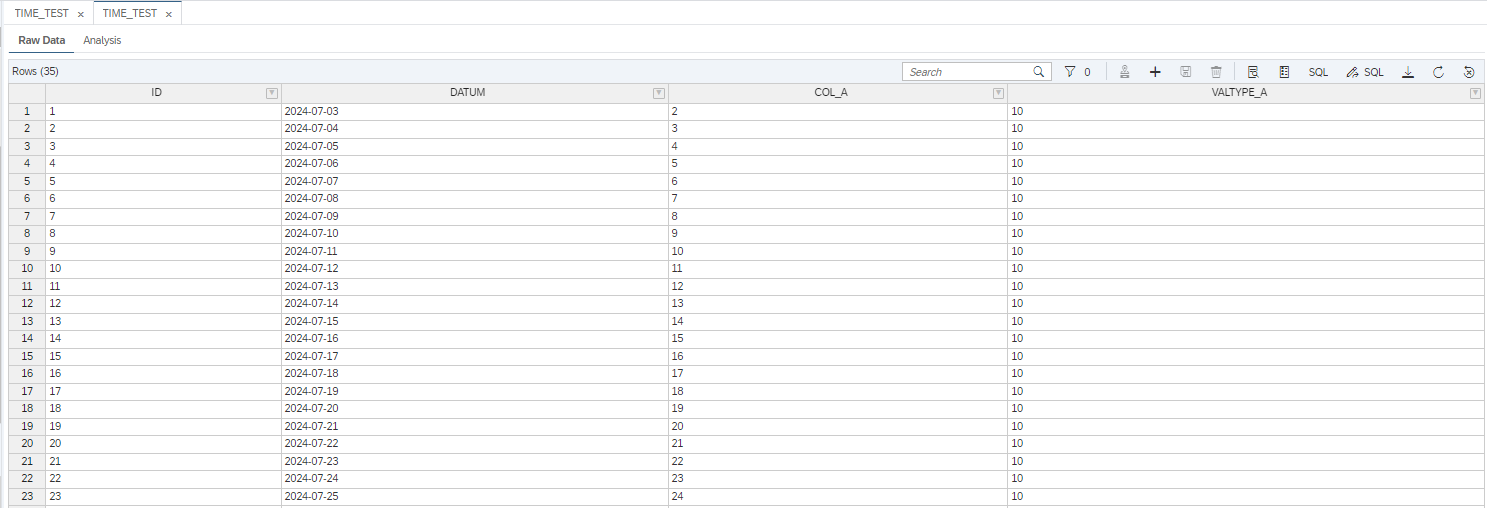
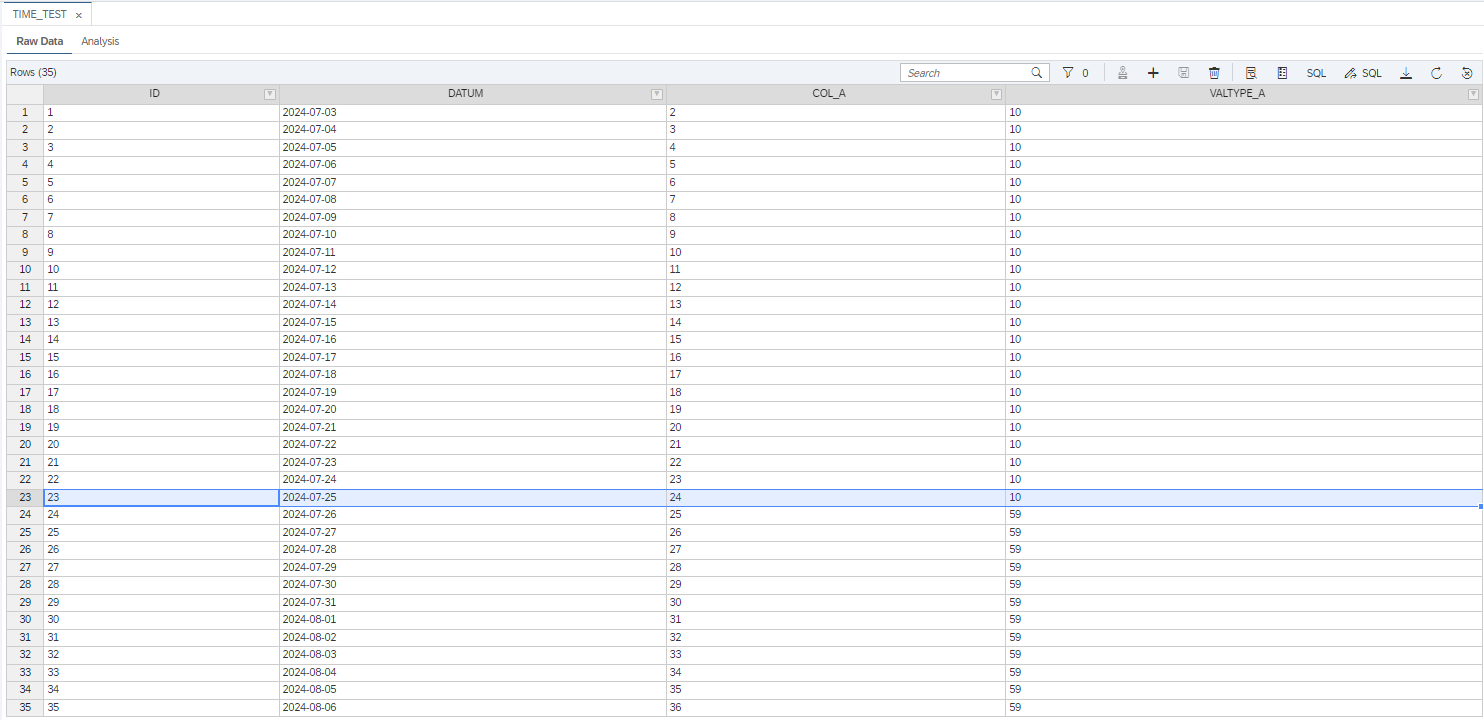
In der SAP HANA Cloud haben wir eine Tabelle „TIME_TEST“ mit den folgenden vier Spalten angelegt:
- ID – Eindeutige Identifizierung eines Datensatzes
- DATUM – Spalte mit Datumsangaben
- COL_A – Spalte mit ganzzahligen Werten
- VALTYPE_A – Spalte mit Werten zur Differenzierung von aktuellen (10) und prognostizierten (59) Werten der Wertespalte „COL_A“.
Die Daten repräsentieren einen täglichen linearen Anstieg der Werte um 1 in COL_A
Entwicklung
Für die Entwicklung auf dem SAP Business Application Studio wurde ein Dev-Space vom Typ „SAP HANA Native Application“ angelegt. In diesem Dev-Space liegt die Pythondatei „timeSeriesAPL.py“. Bevor diese Datei im Terminal über „python timeSeriesAPL.py“ ausgeführt werden kann, müssen die Bibliotheken „hana-ml”, „ipython” und „kaleido” installiert werden.
Dazu wird im Terminal das folgende ausgeführt:
pip install hana-ml
pip install ipython
pip install kaleido
Das Programm, welches erstellt wurde, ist wie folgt aufgebaut:
- Bibliotheken importieren
- Daten auslesen
- Model erstellen und anwenden
- Plot erstellen
- Daten speichern
Bibliotheken importieren
Zuerst erfolgt der Import verschiedener Module aus der „hana_ml“ Bibliothek:
- ConnectionContex wird genutzt, um eine Verbindung zur SAP HANA Cloud zu erstellen, um Daten aus dieser zu schreiben oder zu sichern
- AutoTimeSeries wird genutzt, um eine Forecast Modell zu erstellen und anzuwenden
- Forecast_line_plot wird genutzt, um ein Diagramm der Daten zu erstellen
- Error sammelt auftretende Fehler
Daten auslesen
Nun nutzen wir die „hana_ml“ Bibliothek, um eine Verbindung zur SAP HANA Cloud aufzubauen. Dazu benötigen wir die Adresse der SAP HANA Cloud so, wie sie in der SAP HANA Database Explorer gefunden werden kann, einen Nutzer mit lesendem und schreibendem Zugriff auf die SAP HANA Cloud und das Passwort des Nutzers.
Wir lesen den Datensatz aus der Tabelle „TIME_TEST“ aus und speichern diesen in dem Objekt „df_train“.
Da wir später die maximale ID des Datensatzes brauchen, um die Daten zurückschreiben zu können, lesen wir diese hier aus.
Dazu gehen wir wie folgt vor: wir sortieren dazu die Daten nach der ID absteigend und lesen die erste Spalte aus. Über „.collect()“ wird das Objekt in ein DataFrame aus der Bibliothek „pandas“ konvertiert. Danach nutzen wir dann ebenfalls Syntax aus der „pandas“ Bibliothek , welche in der „hana-ml“ Bibliothek integriert ist, um den Wert der ID auszulesen:
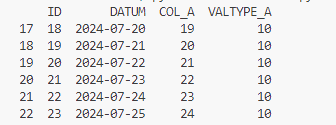
Im Folgenden wird der Trainingsdatensatz auf den Valuetype 10 gefiltert, um das Model nur mit den aktuellen Werten zu trainieren. Daraufhin geben wir die letzten 6 Einträge des Datensatzes im Terminal aus:
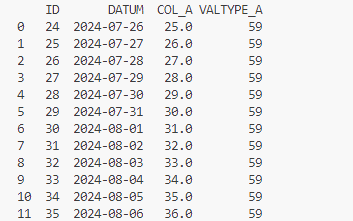
Dies liefert den folgenden Auszug:
Model erstellen und anwenden
Nun erstellen wir das Model für die Zeitreihe. Dazu definieren wir, dass die Zeitwerte sich in der Spalte „DATUM“ und die aktuellen Daten sich in der Spalte „COL_A“ befinden. Den Horizont der Prognose geben wir mit 12 an (horizon = 12), da wir 12 Werte prognostizieren werden. Dann wird das Model anhand des Trainingsdatensatzes trainiert.
Nun wenden wir das Model auf den Trainingsdatensatzes an, um die Daten für die 12 folgenden Tage zu bestimmen. Daraufhin geben wir dann die letzten 14 Zeilen des prädiktiven Datensatzes im Terminal aus:
Dies liefert die folgende Ausgabe mit den Datumswerten, den aktuellen Werten, den prädiktiven Werten sowie einem Fehlerintervall zu den prädiktiven Daten:
Plot erstellen
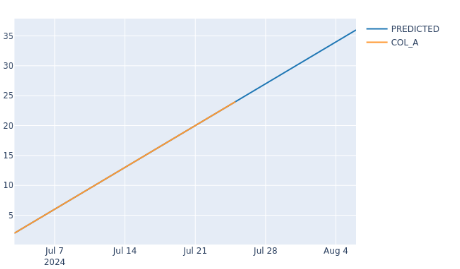
Aus dem Trainingsdatensatz und den prädiktiven Datensatz erstellen wir einen Plot zur Veranschaulichung der Vorhersage. Dazu verwenden wir die Datumswerte beider Datensätze sowie die aktuellen Werte des Trainingsdatensatzes als auch die prädiktiven Werte des prädiktiven Datensatzes:
Wir speichern den Plot als „*.png“ in das Projekt. Die Syntax dazu ist aus der Bibliothek „Plotly“ welche in der „hana-ml“ Bibliothek verwendet wird:
Der folgende Plot liegt dann als „*.png“ Datei im selben Ordner wie die „timeSeriesAPL.py“ Datei vor:
Daten speichern
Um die Daten wieder in die Tabelle zurückschreiben zu können müssen wir die Tabelle „df_pred“ in die Form der Tabelle „TIME_TEST“ bringen.
Dies geschieht, indem die Tabelle auf die Datums Spalte und die Spalte der prädiktiven Werte des Datensets selektiert wird. Die Spalte zum Wertetyp wird hinzugefügt und mit dem Wert 59 befüllt. Danach wird die Spalte der prädiktiven Werte umbenannt und zuletzt wird die ID Spalte hinzugefügt:
Nun sind die Spalten der Tabellen identisch. Um später beim Speichern Probleme mit den Datentypen zu umgehen, konvertieren wir die prognostizierten Daten einmal in den Datentyp „real“. In unserem Beispiel wurde ein Werte von 25.0 prognostiziert da diese aber im Datentyp „DOUBLE“ als 24,999… vorliegen, werden diese dann als 24 verbucht, wenn direkt in BIGINT konvertiert wird:
Jetzt filtern wir auf die neuen Datensätze indem wir die maximale ID aus dem Kapitel „Daten auslesen“ verwenden. Die Daten geben wir einmal im Terminal aus:
Dies liefert die folgende Ausgabe:
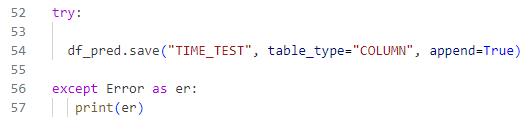
Zuletzt speichern wir die neuen Werte in der Tabelle „TIME_TEST“ und fangen Fehler ab:
Schließlich beenden wir die Verbindung zu SAP HANA Cloud:
Fazit
In weniger als 100 Zeilen Code haben wir ein Programm entwickelt, dass Daten ausliest, Berechnungen einer Zeitreihe durchführt, diese visualisiert und die Daten speichert. Dieses Programm kann als Grundlage für Anwendungen dienen, die mit komplexeren Daten arbeiten.
Dazu wird im Terminal das folgende ausgeführt:
Wir haben hier in einem einzigen Programm ein Modell erstellt und direkt angewendet. Für andere Szenarien empfiehlt es sich jedoch, das Modelltraining und die Anwendung zu trennen und gegebenenfalls zu erweitern. Auf dieser Basis können Anwendungen für komplexere Szenarien entwickelt werden, da die „hana_ml“ Bibliothek mit den APL- und PAL-Paketen eine Vielzahl von Machine Learning-Algorithmen bietet, darunter Klassifikation und Textverarbeitung.
Die Flexibilität und Erweiterbarkeit dieses Grundgerüsts ermöglicht es, spezifische Anwendungsfälle effizient zu bearbeiten und so maßgeschneiderte Lösungen für unterschiedliche Datenanalyseanforderungen zu schaffen.